The Problem
While large language models (LLMs) like GPT-4 demonstrate impressive capabilities in generating English text, their performance in other languages, especially less-represented ones, can be lacking. Bengali, or 'Bangla' to natives, is a prime example. Despite being one of the most spoken languages globally, Bangla suffers from a scarcity of digitized content. Our project aims to create a high-quality Bangla text corpus, akin to the TinyStories dataset (link).
Solution Overview
The original TinyStories project harnessed GPT-3.5 and 4 to produce synthetic English data. However, given GPT's limited Bangla generation capabilities, we've devised a different approach involving two key steps:
- Use GPT-4 to translate each story from the TinyStories dataset into Bangla.
- Manually verify each story for linguistic and logical accuracy.
Opting for translation over direct Bangla text generation has proven more reliable. To facilitate this, we developed a software system comprising two components:
Data Synthesis
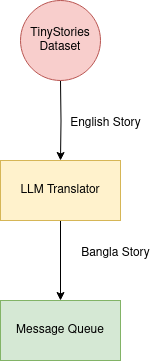
As shown in the diagram above, we have a background data synthesis process which takes the following steps:
- Extract a story from the TinyStories dataset.
- Translate the story into Bangla using an LLM.
- Store the translation in a message queue.
Draft Editor
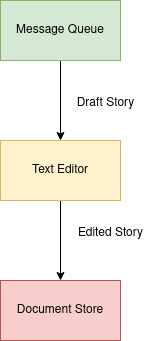
The second piece of our software involves a web application for verifying the translated stories. As shown in the above diagram, it works as follows:
- A pregenerated story is retrieved from the message queue into an online text editor.
- Our verifiers edit and refine these drafts in the editor.
- Once finalized, the stories are saved in a NoSQL document store.
Impact & Learnings
This project demonstrated both the challenges and opportunities in creating synthetic datasets for low-resource languages. The combination of machine translation and human verification proved to be an effective approach for generating high-quality Bangla text data, potentially serving as a model for similar initiatives in other languages.